Render Hell – Book II (Architecture)
- “작은” GPU 코어가 모든 작업을 처리하지는 않는다.
- 여러 개의 병렬로 실행되는 파이프라인이 있을 수 있다.
- GPU는 매우 매우 복잡하다.
- Application Stage
- Driver Stage
- Read commands
- Data Fetch
- Vertex Fetch
- Shader Execution
Render Hell – Book II를 읽고 정리한 내용이다.
1권에서 Pipeline에 대한 내용은 완전히 틀리지는 않지만 명확하지 않은 부분이 있다. 이번에는 다음 두 가지 주제를 중심으로 더 자세히 설명한다.
- “작은” GPU 코어가 모든 작업을 처리하지는 않는다.
- 여러 개의 병렬로 실행되는 파이프라인이 있을 수 있다.
“작은” GPU 코어가 모든 작업을 처리하지는 않는다.
사실 대부분의 작업은 GPU 코어가 수행하지 않는다. 이미 1권의 “더 빠른 메모리로 데이터 복사” 문단에서 데이터를 코어로 가져오려면 몇 가지 구성요소가 필요하다는 것을 보았다.

코어는 명령과 데이터를 받아 floating point unit (FP UNIT) 또는 integer unit (INT UNIT)으로 데이터를 계산한다. 따라서 코어는 픽셀과 정점을 계산할 수 있다. 그 외에 렌더 작업을 분할하거나, 테셀레이션(Tessellation), 컬링, 레스터화(Rasterizing) 등은 GPU 내에 있는 프로그래밍 불가능한 하드웨어 블록들이 수행한다.
여러 개의 병렬로 실행되는 파이프라인이 있을 수 있다.
GPU 코어는 혼자서 동작할 수 없다. 누군가 작업을 할당해야 한다. 코어에게 작업을 할당하는 유닛이 바로 Streaming Multiprocessor다. Streaming Multiprocessor는 하나의 셰이더에 속하는 정점/픽셀 스트림을 처리할 수 있다. Streaming Multiprocessor는 여러 개의 코어를 가질 수 있고 따라서 여러 개의 정점과 픽셀을 동시에 처리할 수 있다.

그리고 만약 Streaming Multiprocessor가 더 있고 그에게도 GPU 코어가 할당되어 있다면 동시에 2개 이상의 쉐이더 스트림을 처리할 수 있게 된다.

이 대략적인 예는 여러 가지 하드웨어 블록이 병렬로 작동하므로 파이프라인이 더 유연하다는 것을 보여준다. 유연하고 병렬적인 파이프라인이 필요한 이유는 GPU는 다양한 작업을 처리할 수 있고 다음에 어떤 작업을 할지 예측할 수 없기 때문이다. 예를 들어 테셀레이션을 사용하는 경우 갑자기 10만개 이상의 폴리곤이 생겨날 수 있다. 이런 상황에서도 유연하게 동작하는 파이프라인이 필요하다.
GPU는 매우 매우 복잡하다.
아래 이미지는 GPU를 보여준다. 뭐가 뭔지 모르겠다. Life of a triangle에서 GPU의 구조도 확인할 수 있다. 매우 복잡하다는 것을 알 수 있다. 이를 통해 GPU가 얼마나 복잡한지와 아래 설명이 얼마나 간략화되었는지 알기를 바란다.

Application Stage
파이프라인은 어플리케이션이 드라이버에게 Draw call이나 렌더 상태를 변경하는 명령을 전달하면서 시작된다.

Driver Stage
드라이버는 받은 명령을 잠시 후 또는 프로그래머가 강제한 시점에 Command buffer에 넣는다.

Read commands
이제 그래픽 카드의 Host Interface가 명령을 읽어서 사용할 수 있도록 만든다.

Data Fetch
GPU로 전송되는 명령 중 일부는 데이터를 포함하거나 데이터를 복사하라는 명령이다. GPU에는 일반적으로 RAM과 VRAM간 데이터 복사를 처리하는 전용 엔진이 있다. 이 데이터는 vertex buffer, 텍스쳐, 쉐이더 매개변수 등이 될 수 있다. 프레임은 일반적으로 camera matrices 데이터가 전송되면서 시작한다.
- 정점 데이터는 vertex buffer로 불리는 “정점 목록”으로 표현된다.
- 텍스쳐는 VRAM에 아직 그 텍스쳐가 없는 경우에만 복사된다.
- 정점 버퍼가 많이 사용된다면 VRAM에서 제거되지 않고 상주하게 할 수 있으며 복사할 필요가 없게 된다.
- 정점 버퍼가 많이 변경되는 경우 RAM에 남아 있으면서 GPU는 RAM에서 캐시로 직접 데이터를 읽을 수 있다.
데이터가 모두 준비되면 Gigathread Engine이 작동해서 각각의 정점/픽셀에 대한 처리를 하는 스레드들을 생성해서 패키지로 묶는다. NVIDIA는 이 패키지를 “스레드 블록(Thread Block)”이라고 부른다. 이 스레드 블록은 Streaming Multiprocessor에게 배포된다.
Vertex Fetch
Streaming Multiprocessor를 구성하는 한 요소인 “Polymorph Engine”이 필요한 데이터를 VRAM 등에서 가져와 캐시에 복사한다. 코어는 캐시에 빠르게 접근할 수 있기 때문에 더 빠르게 동작할 수 있게 된다.
Shader Execution
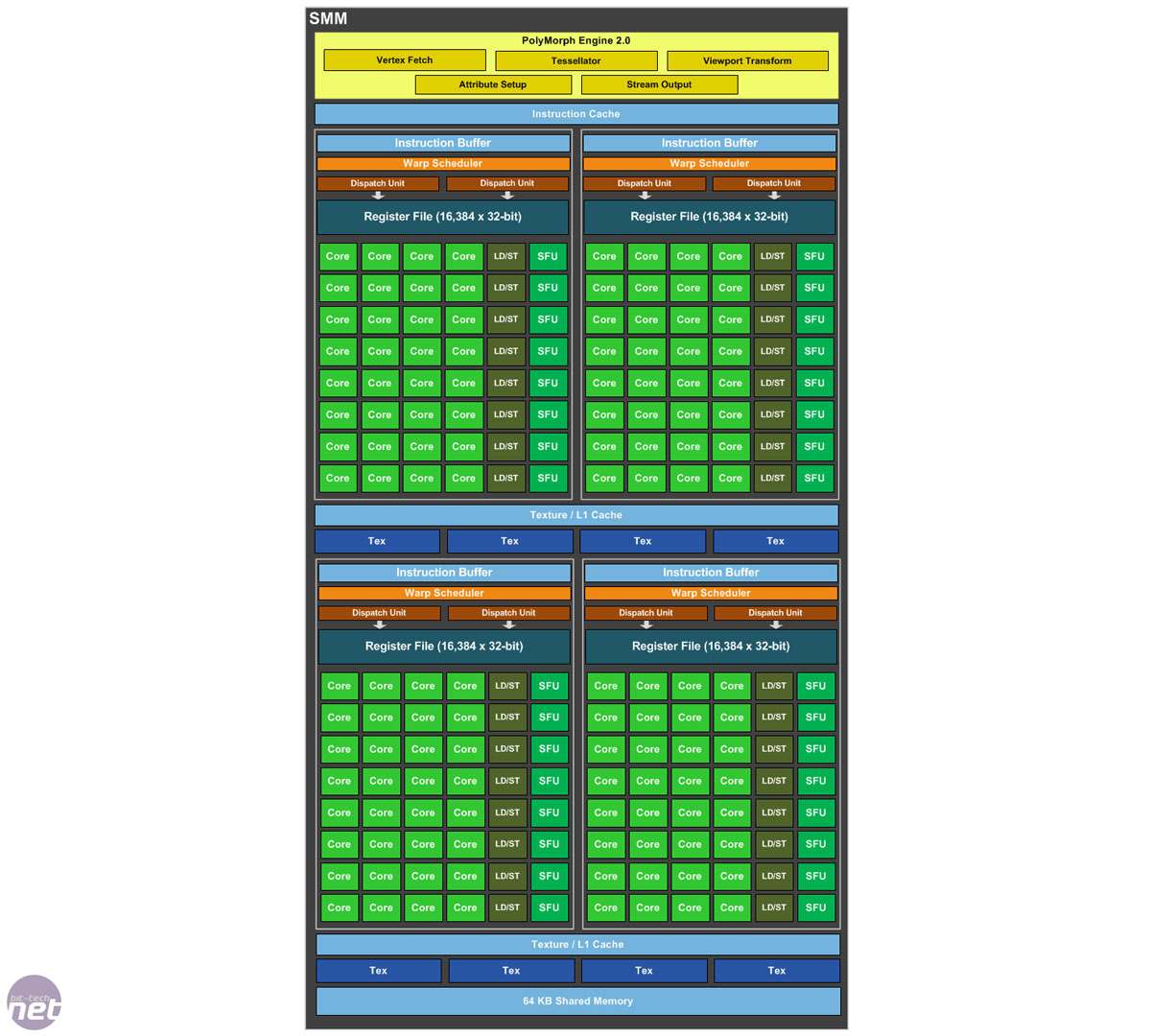
Streaming Multiprocessor의 주요 목적은 개발자가 작성한 프로그램(쉐이더 라고 하는)을 실행하는 것이다. Streaming Multiprocessor는 Gigathread Engine에게서 받은 스레드 블록을 32개의 스레드로 묶은 heap으로 나눈다. 이 heap을 “Warp”라고 한다. Streaming Multiprocessor 이러한 Warp를 64개 “보유”할 수 있다. 이 예에서는 32개 스레드에서 동작하는 32개 코어가 있다.
그 다음 Wrap를 하나 가져와서 수행하기 위해 모든 데이터를 레지스터에 로드한다. 이 예에서는 간략화 되었지만 예를 들어 Maxwell의 Streaming Processor는 4개의 Warp 스케쥴러를 갖고 있으며 각각의 스케쥴러는 한 Warp를 수행한다.
이제 코어는 실제 작업을 시작한다. 코어는 전체 쉐이더 코드를 볼 수 없고 Streaming Multiprocessor에 의해 한 번에 하나씩 명령을 제공받는다. 따라서 Streaming Multiprocessor에 속한 모든 코어는 동시에 동일한 쉐이더 코드를 하나씩 실행한다. 다만 코어별로 서로 다른 정점이나 픽셀에 대해 코드를 실행한다. 따라서 일부 코어가 A 코드를 실행하는 동안 다른 일부 코어가 B 코드를 실행하는 것은 불가능하다.

if문이 있는 경우 조건에 따라 일부 코어가 서로 다른 코드를 처리해야 할 경우가 생긴다. 그러나 동시에 다른 코드를 실행할 수는 없으므로 한쪽의 코어가 실행되는 동안 다른쪽의 코어들은 유휴 상태가 된다. 이러한 상황을 최소화해서 가능한 유휴 상태가 되는 코어가 없도록 해야 한다. 가장 이상적인 상황은 모든 스레드가 if문의 한쪽 코드만 처리하게 되는 경우다.

코어는 한 번에 하나의 코드만 수행할 수 있지만 Streaming Multiprocessor는 64개의 Warp를 가지고 있다. 그 이유는 코드를 실행하는 도중 데이터를 대기하는 시간 동안 다른 Warp를 실행하기 위함이다. 데이터를 기다리는 동안 코어를 쉬게 하는 대신 다른 Warp를 처리하도록 해서 효율성을 높이는 것이다.
이 그림처럼 Streaming Processor(SMM)는 4개의 Warp 스케쥴러를 갖기 때문에 동시에 4개의 Warp가 완전히 병렬적으로 실행될 수 있다. 여기에 명령어 수준의 병렬성도 있다. 코어가 명령을 처리하는 동안 코어 내의 리소스를 사용할 수 있는 경우 새로운 명령을 받을 수 있다. 이를 통해 4개 이상의 Warp가 병렬적으로 실행될 수 있다. 실제로 GTC2013의 CUDA 최적화 영상 중 하나에서는 일반적인 경우 파이프라인을 완전히 점유하도록 유지하기 위해 30개 이상의 활성 워프를 권장합다.

{kind=link}